Intro
Stay tuned, more to come in this post :)
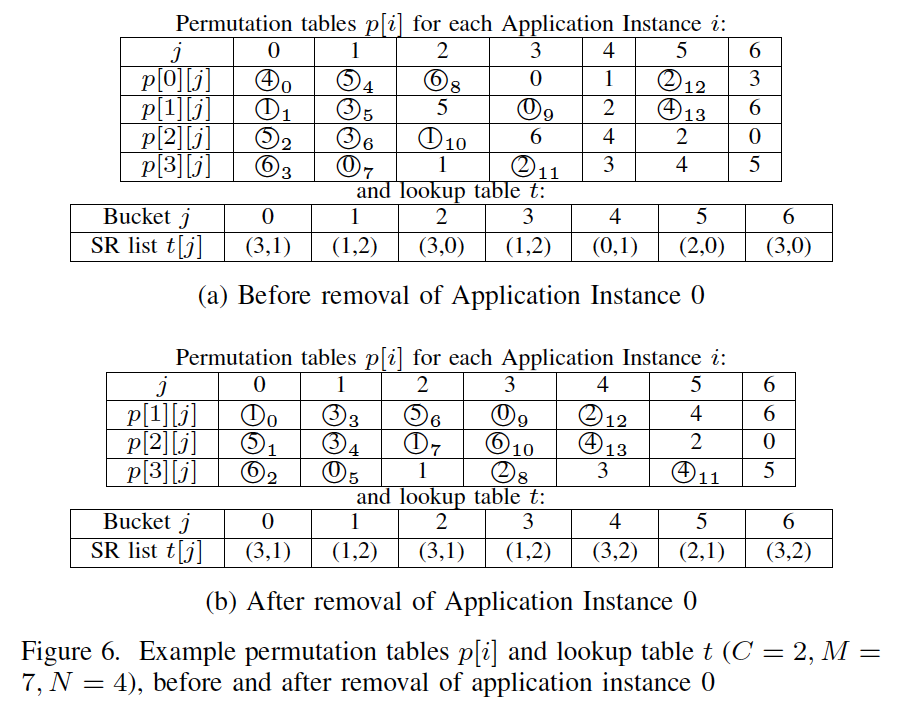
6LB is a load-balancing approach that is application server load aware, yet is both application and application-layer protocol independent and does not rely on centralized monitoring or transmission of application state. It is authored by Yoann Desmouceaux, et al., under supervision of Mark Townsley and Thomas Clausen. This blog is posted to consolidate my understanding of the consistent hashing algorithm used in 6LB.
Consistent hashing is used, for instance, in Maglev (Ref [2]), which proposes an algorithm mapping an incoming flow to one application instance. And a new consistent hashing algorithm which generalizes the one from Maglev is introduced in 6LB.
To be clear, 6LB uses 2 choices of application instances. However, the algorithm presented is agnostic to this value, and is therefore presented for lists of C instances.
Algorithm
Before presenting the algorithm, notations used through the algorithm are summarized below in the table.
| Notation | Description |
|---|---|
| M | Number of buckets |
| N | Number of servers |
| C | Size for segment routing list |
| i | Application instance, range [0, N-1] |
| j | Bucket, range [0, M-1] |
| p[i] | Pseudo-random permutation of {0, 1, …, M-1} for application instance i |
| t | Lookup table {0, …, M-1} ➡ {0, …, N-1}$^C$, mapping each bucket to a list of C application instances |
| t[j] | An array of C application instances, e.g. for bucket j, there will be C application instances in its codomain in table t |
| nextIndex | This array lists the next index in each application’s permutation p[i] so as to indicate which bucket should each application instance take next time |
| n | Counter for total assignments |
| c | A tmp variable, denoting current bucket of interesting |
| choice | A tmp variable, denoting the first avvailable position in the SR list |

In this consistent hashing algorithm, there are two main sections, namely, initialization and main loop, which are introduced sequencially.
Initialization
In terms of the demonstrated algorithm, four variables are initialized.
$nextIndex$
$nextIndex$ is initialized as an array, with length of total number $N$ of application instance. The values inside are all set as $0$ so that for each application instance, its bucket of interest start from the first one in its permutation.
$C$
As is mentioned above, $C$ represents the size for segment routing list. Here, $C = 2$ means that there will be two application instances in the segment routing list.
$t$
Now that $C$ is set to $2$, we could now initialize our table $t$. It is initialized as a M x C matrix, where M represents the number of buckets, and C stands for the size for SR list. All the values are initialized as $-1$, which means that no application instance has been assigned to this position. If none of the values in a row is $-1$, then this corresponding bucket is already full.
$n$
Also as is mentioned above in the notation talbe, $n$ represents the total number of times that application is assigned to a bucket. Its value is initialized as $0$. And once $n = M \times C$, it indicates that the table $t$ is fully assigned.
Main Loop
The main purpose for this algorithm is to balance the distribution of application instances into different buckets. There are two outer loops guarantee this to happen, namely, the tier-1 while loop and the tier-2 for loop.
The while loop is used to traversal all application instances from time to time, meanwhile, it’s used in case not all buckets are fully filled with application instances after traversal of all application instances. In the for loop, there are several condition-checking and loops, trying to find a vacant position in the buckets for an application instance.
The logic in behind will be clearly demonstrated with an example below.
Example