Intro
This note discusses about the server model that I used in a data center (DC) simulator. This model is queue-based and has multiple processing efficiency stages. For each given task with an expected job complete time or flow complete time (FCT), the actual FCT (expected FCT + additional FCT) may vary because of constrained server capacity as well as actual number of on-going jobs (or network flows).
Notation
Before digging into details, we define the following variables and give their corresponding explaination:
fct_exp: expected flow complete timefct_add: additional flow complete timefct_act: actual flow complete time, which is equivalent tofct_exp+fct_addfct_res: residual flow complete time#flow: number of on-going flows on the server, at a given timestampt, we denote its corresponding number of established flows as#flow(t)#thread: number of threads (or workers), which determines how many flows can be processed at the same time with 100% efficiency#backlog: maximum number of flows that can be processed by#threadin a multi-threading setup#max_wait: maximum number of flows that could be blocked and wait to be processedt_arrival: the timestamp of a flow’s arrival on the serverlifetime: a flow’s lifetime on the server, which is an interval between [t_arrival,t_arrival+fct_act]PE(#flow): a function that maps#flowto processing efficiency
Queueing Model
Each application server has two queues for incoming flows, that are, processing queue and blocking queue. For an idle server, any newly-arrived flow will be directly enqueued into processing queue, which stores flows that are currently under process. Once the flow is finished, it will be dequeued from the processing queue and the result will be replied to the client. The processing queue’s length is #backlog. If the processing queue became full, flows will be put into the blocking queue, which is a first-in-first-out (FIFO) queue. Whenever a flow is finished processing and dequeued from the processing queue, which becomes available, the first flow in the blocking queue will be popped and enter the processing queue. The blocking queue has length of #max_wait. If the blocking queue was full, then the newly-arrived flow will be dropped.
Calculate Processing Efficiency
There exist the following models in queueing theory when we model application server.
FIFO
First-in-first-out (FIFO) is the most common model (e.g. Apache webserver works like this). When queries arrive at the application server, each worker (thread) deals with one query. If all available workers are busy, then new queries are stalled until any of the busy threads became available again. Therefore, PE is always 1 for queries that are being processed and it is always 0 if queries are stalled. FCT for each flow thus consists of actual processing time and stalling time waiting in the queue.
Processor Sharing
In a pure multi-threading setup, tasks share processing capacities even if the amount of tasks surpass the number of workers. The main idea of this model is to pretend that there are always #flow workers on the application server so that each flow can be processed independently. However, the processing efficiency will be divided by actual number of tasks once the number of flows exceeds the number of workers. Therefore, the FCT of each flow is calculated by integrating processing time with corresponding processing efficiency throughout its lifetime.
2-Level Processor Sharing
A more complicated model is a hybrid model of FIFO and processor sharing. The processing efficiency function PE(#flow) is depicted in the figure below.
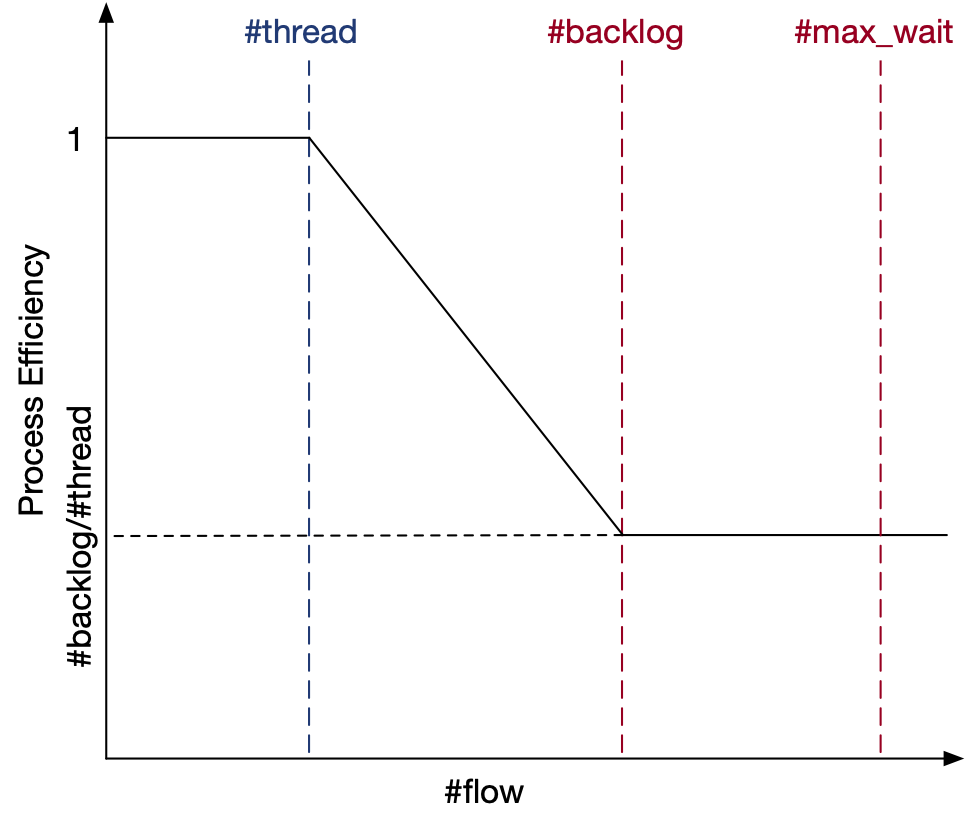
If #flow <= #thread, we have enough workers for all the flows. If this is the case throughout the flow’s lifetime on the server, then its fct_add = 0 and fct_act = fct_exp.
If #thread <= #flow <= #backlog, we don’t have enough workers for all the flows any more and #thread workers need to be splitted across all the flows in multi-threading setup. If this is the case throughout the flow’s lifetime on the server, then its fct_act could be calculated with the following algorithm iteratively:
get fct_exp, t, flow_id, events
fct_res <- fct_exp
pe <- PE(#flow(t))
t0, t_last <- t
while fct_res > 0:
t, is_done <- yield events.enqueue(flow_id, flow2finish(t+fct_res/pe)) # this yield is triggered to return in two cases, a) the flow is done, b) there is a change of `PE`.
if is_done:
break
else:
events.pop(flow_id)
fct_res <- fct_exp - (t - t_last) * pe
assert fct_res > 0
pe <- PE(#flow(t))
t_last <- t
return t - t0
A bit of explaination here. After initialization, we have all necessary information about the flow, and the queue events in which stores a list of events (sorted by triggering timestamps) in our event-based simulator. Before the flow finishes being processed, whenever there’s a change of processing efficiency, we calculate residual job to do, re-estimate time to finish with the new processing efficiency and update the corresponding event.
Then, if #backlog <= #flow <= #max_wait, another element will be added to fct_add, that is, pending time in the block queue before the flow gets pulled into the processing queue.
Finally, if #flow > #max_wait, we set fct_act as \(-1\).
Discussion & Conclusion
The reality could be much more complicated than our model. For instance, in our simulator, we tend to assume that server capacities are modularized and are always multiples of a unit processing efficiency. However, each hardware might have different characteristics. At the mean time, at different time steps, there might be various background processes running on servers. We could tune this by e.g. adding external constraints on PE function by injecting PE multiplier changing events.
In this note, we talked about the queueing model, processing efficiency and FCT calculation on the server side. The next steps towards a more realistic DC simulator will to recap and think about the model of each network flow (e.g. what are the important attributes that could give us minimal yet complete information to analyse performance), transmission delay, and middle boxes functions.
Cheers! :)