
- Link2Paper
- [Author: Qun Huang et al.]
- [Keywords: Network Measurement, Sketch]
Motivation
Network measurement is challenged to fulfill stringent resource requirements in the face of massive network traffic. While approximate measurement can trade accuracy for resource savings, it demands intensive manual efforts to configure the right resource-accuracy trade-offs in real deployment. Such user burdens are caused by how existing approximate measurement approaches inherently deal with resource conflicts when tracking massive network traffic with limited resources. In particular, they tightly couple resource configurations with accuracy parameters, so as to provision sufficient resources to bound the measurement errors. Such tight binding leads to several practical limitations:
- administrators need to specify tolerable error levels as input for resource configurations;
- each configuration is tied to specific parameters (e.g., thresholds);
- the theoretical analysis only provides worst-case analysis and fails to guide the resource configurations based on actual workloads;
- each configuration is fixed for specific flow definitions;
- administrators cannot readily quantify the extent of errors for measurement results.
Contribution
Problem
Design Requirement
- Small memory usage;
- Fast per-packet processing;
- Real-time response;
- Generality.
Limitations of Existing Approaches

- Hard to specify expected errors (theoretical guarantees based on configurable parameters);
- Performance degrades with different threshold (e.g. heavy hitter detection);
- Hard to tune configurations;
- Hard to re-define flowkeys (5-tuple, src-dst addr pairs, …);
- Hard to examine correctness.
Solution
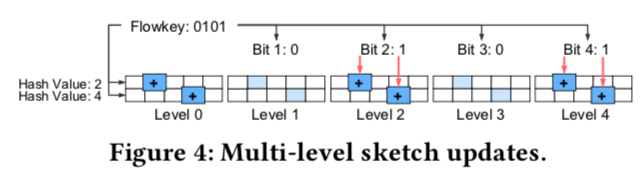
- Multi-level Sketch (makes it possible to quantify hash collisions, bit-level flowkey distributions)
- Model Inference (their assumptions require to separate large and small flows)

Evaluation
Testbed
OVS, P4. Simulator is used for larger scale test (eliminates network transfer overhead).
Traces
CAIDA [1] and UN2 [2].
Experiments
- Memory usage

- Per-packet processing
- Testbed throughput
- Simulator throughput
- Inference time
- Generality

- Fitting theorems
- Robust to small thresholds

- Arbitrary field combinations
- Attaching error measures
- Network-wide coordination

Source code
Link to github repo. Respect! :)
Limitation
- Default parameters are limited
- Does the model inference algorithm converge, especially with larger number of rows?