
Videos Available Online
The video presentation of our paper at NeurIPS 2022 main conference is currently available online on 3 platforms:
- Youtube: For international users!
- BiliBili: 中文用户请看这里 (For Chinese users behind the WALL!)
- SlidesLive: This is actually the official platform of video presentations at NeurIPS. Sadly, because of a technical issue of SlidesLive, their site is only accessible using Chrome as the browser…
Oh! By the way, our camera-ready version of the final paper is now available on ArXiv. Feel free to check it out as well!
Transcription
For those who enjoy consuming information in another modulation with low bandwidth – i.e. in text – I will put the transcription of my presentation here with my slides.
Introduction
Hello! I am Zhiyuan, from École Polytechnique and Cisco Systems. I will briefly present our paper: “Learning Distributed and Fair Policies for Network Load Balancing as Markov Potential Game” in NeurIPS 2022.
Background
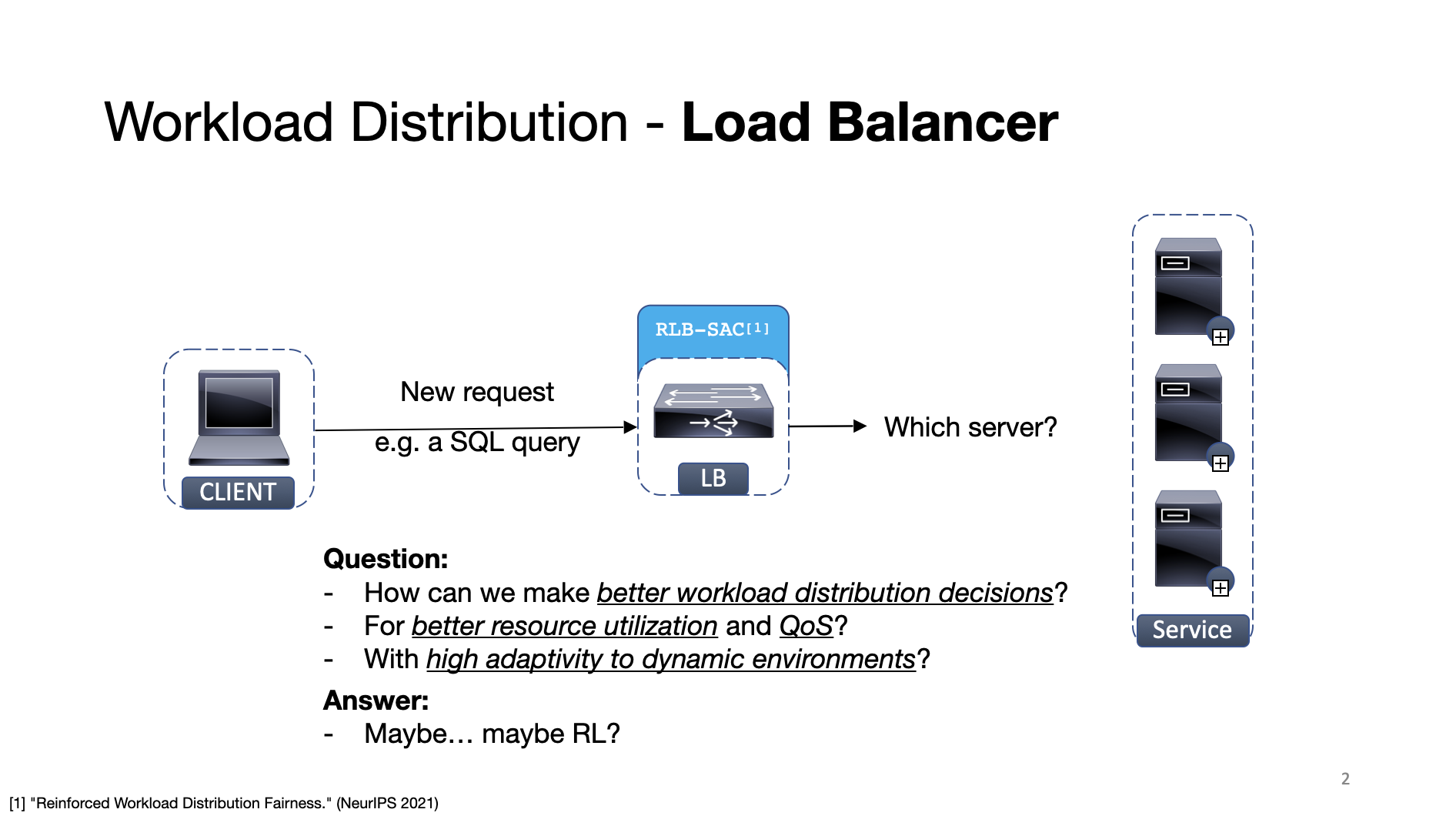
First, let me introduce the network load balancing problem in data center networks. On receipt of a new request (e.g. a SQL query), the load balancer need to decide which server will handle the new request.
Decisions could be made based on the queue length on the servers. However, servers can have different processing capacities, which is an unknown information for the load balancer.
To improve the QoS and resource utilization under elastic and dynamic networking environments, a RL-based load balancing algorithm — RLB-SAC — was proposed last year to make better workload distribution decisions.
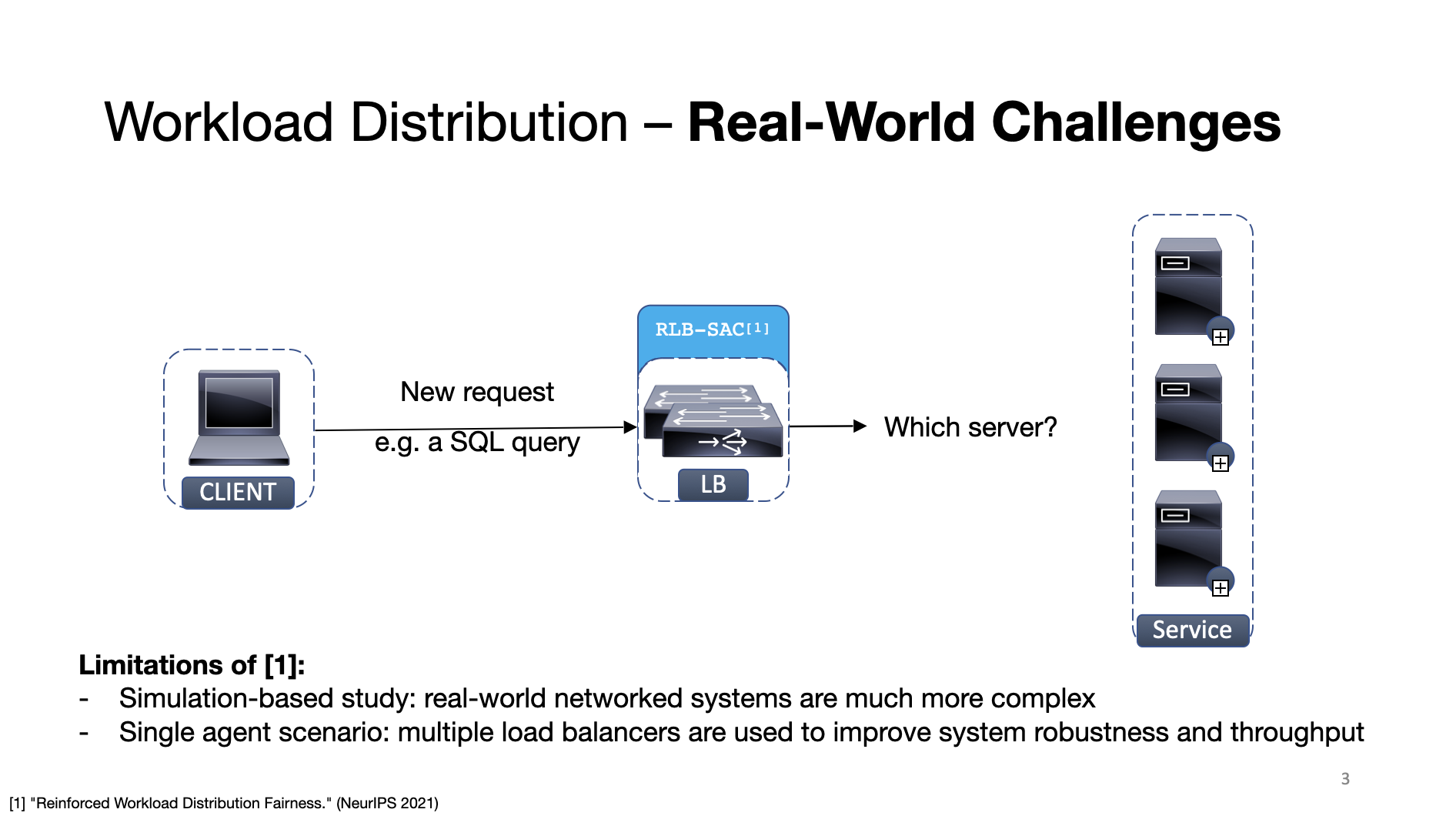
However, RLB-SAC is evaluated on simulators instead of on real-world systems. And it focused mainly on single agent scenarios while in real-world systems, multiple load balancer agents are deployed to avoid single point of failure, which can directly lead to the problem of partial observations.
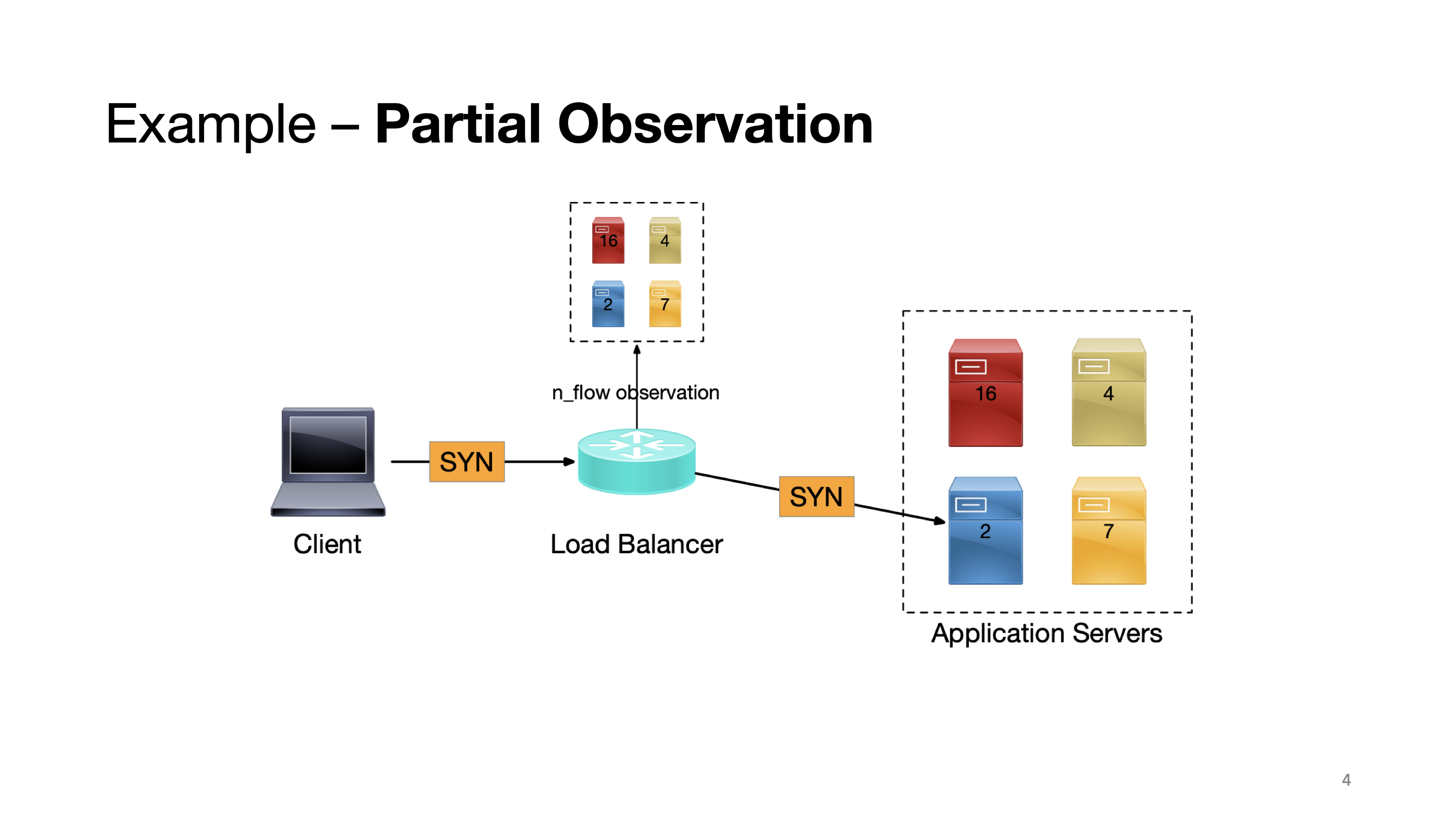
For instance, when there’s only a single load balancer agent, it has global observation on the server queue lengths.
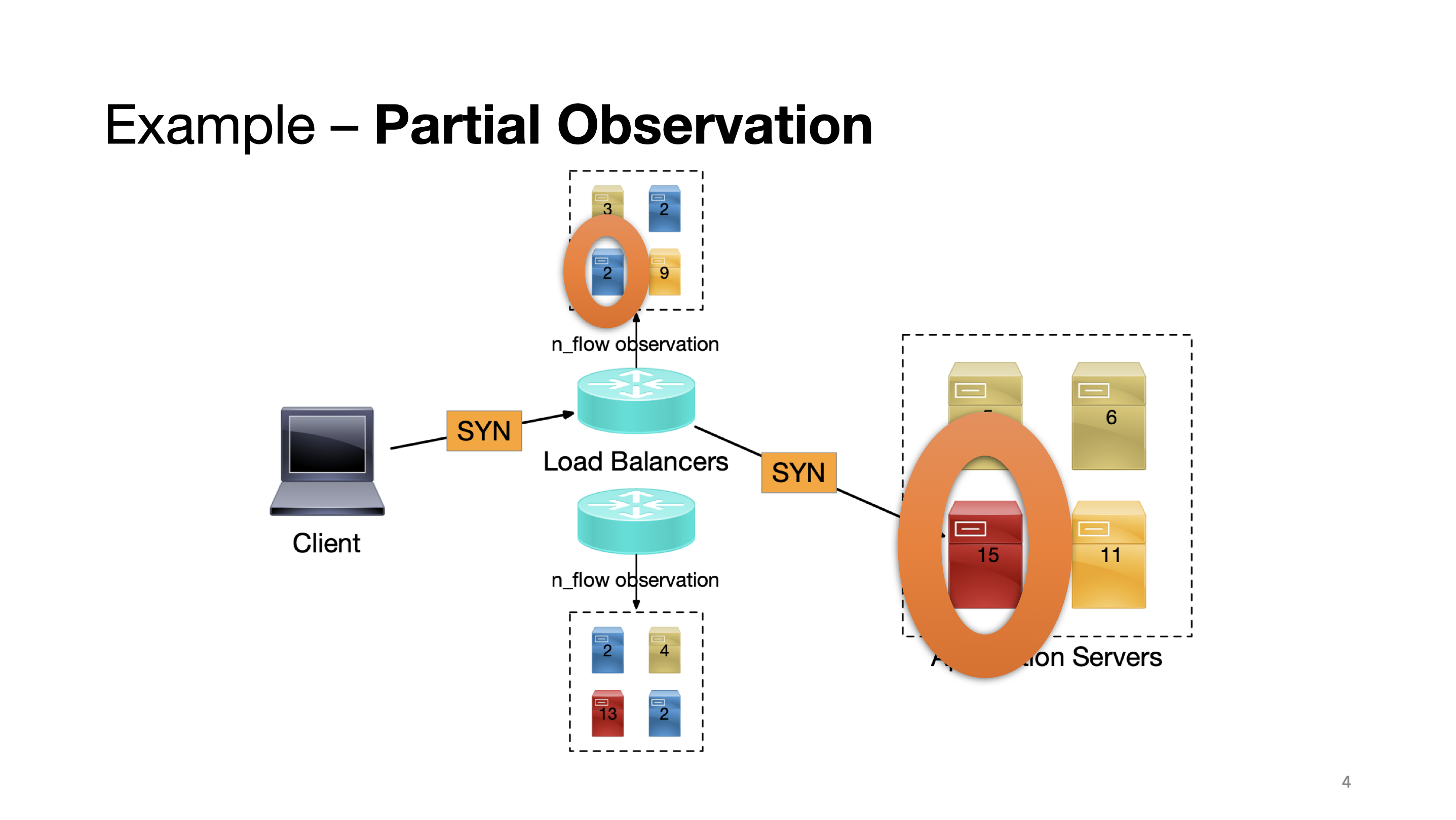
However, when traffic is split among the two load balancers deployed in the system, each load balancer has only a partial observation. And in this case, the load balancer on the top will mistakenly consider that the circled server is less loaded, while in reality, it is the most utilized server.
Model

To understand the load balancing problem, we study a queuing model, where we define m load balancers and n servers. With the workload assigned to each server, whose processing speed can be different, we can derive the expected time to finish all the workload on a given server.
For instance, given a timestamp t_n, we can get the highlighted part as the expected time to finish for server 0 and server 1.

Then our objective is to find the optimal policy that minimize the cost function C given all the server load states. And the cost function is conventionally defined as the “makespan”, or the max server load state in the system.
So this is the theoretical model. But in real-world systems, what are the additional constraints?
Real-World Constraints

First, network load balancers operate at the Transport layer and do not have application-level information. Thus no makespan can be computed on network load balancers. Instead, we can only rely on the limited observations, namely, the number of on-going jobs and a distribution of job durations.
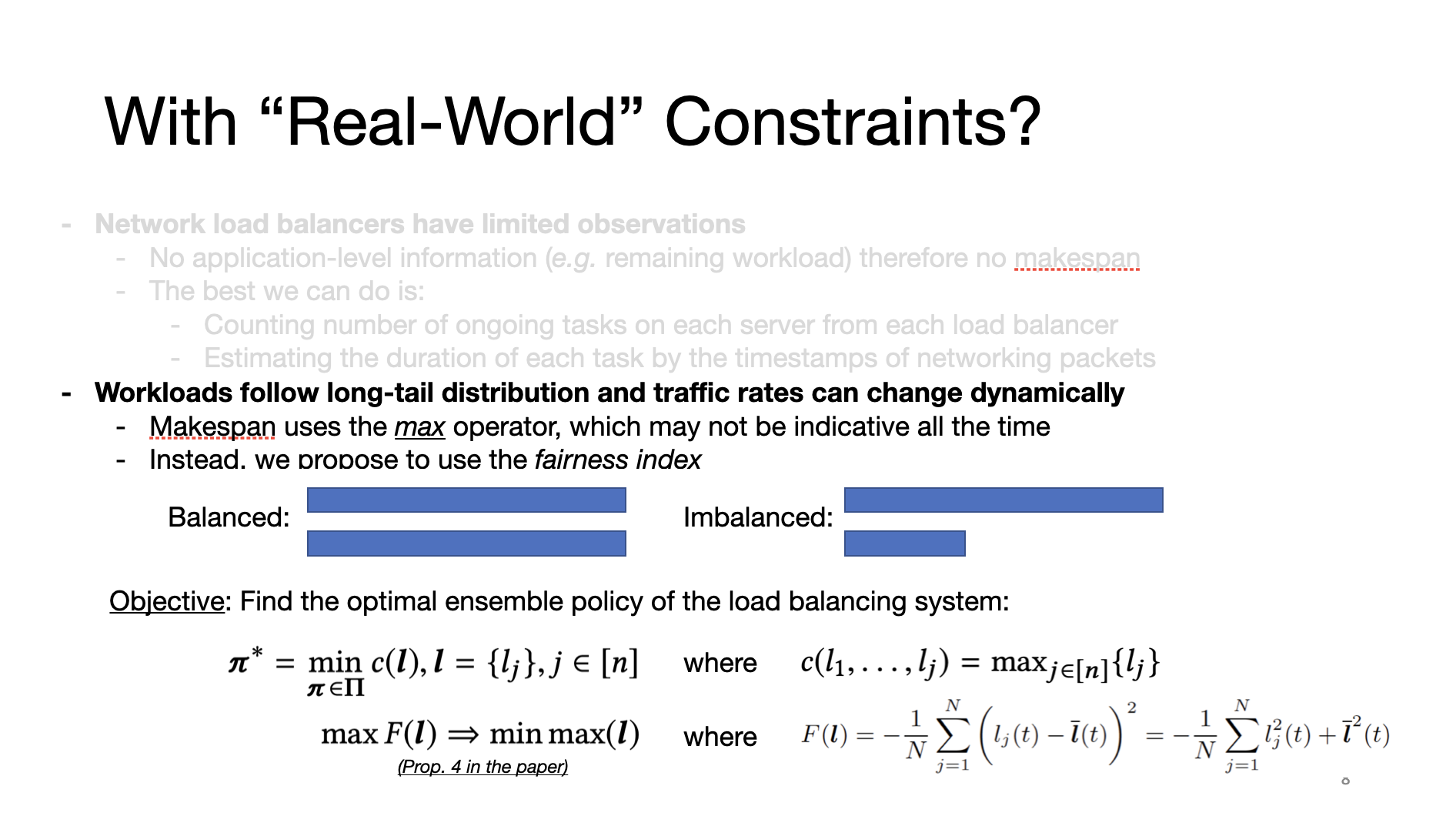
Second, in the context of networking environments, the workload follows long-tail distribution and the traffic rates can be quite bursty. Makespan fails under this scenario, for instance, the two different cases yield the same makespan, which makes makespan a less desirable reward for RL models. Therefore, we propose to use the variance-based fairness index to evaluate the overall workload distribution in the system.

Third, we’ve discussed about the problem of multiple agents and partial observations. Centralized-training distributed-execution algorithms have been proposed to tackle these issues. However, in networking systems in production, they can incur significant communication overhead, especially in large-scale data center networks. Therefore, we prefer to build independent agents which can cooperate to achieve pure Nash equilibrium based only on local information. And this is the charm of the Markov Potential Game, where we have proved that the variance-based fairness satisfies the requirements as a potential function.
Design
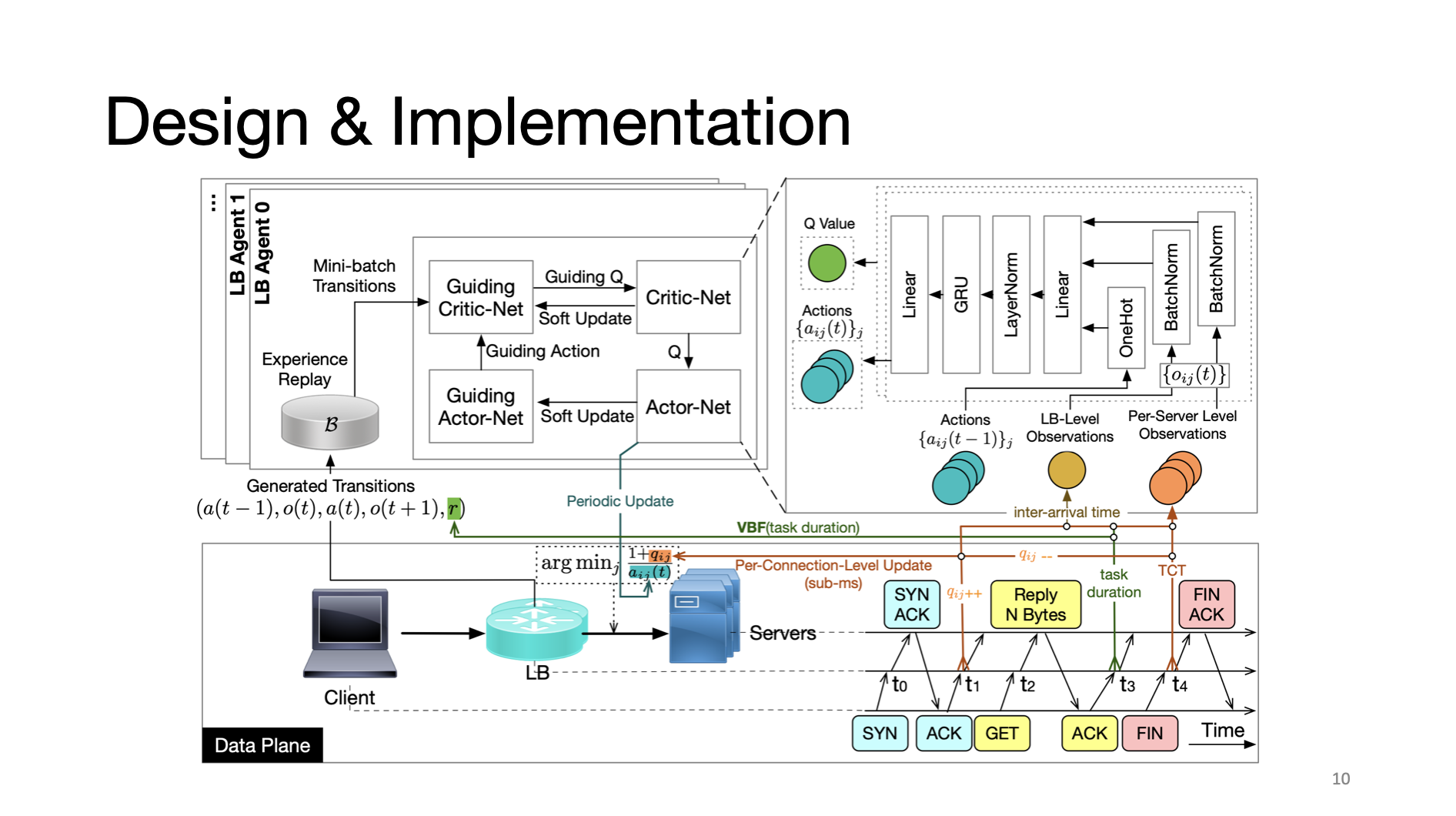
The proposed Multi-Agent Reinforcement Learning framework that we implemented in the real-world system is shown in this figure. We extract networking features from the data plane so that the reinforcement learning agents are able to infer server load states in real time, and make informed load balancing decisions. More details about this workflow can be found in our paper.
Results
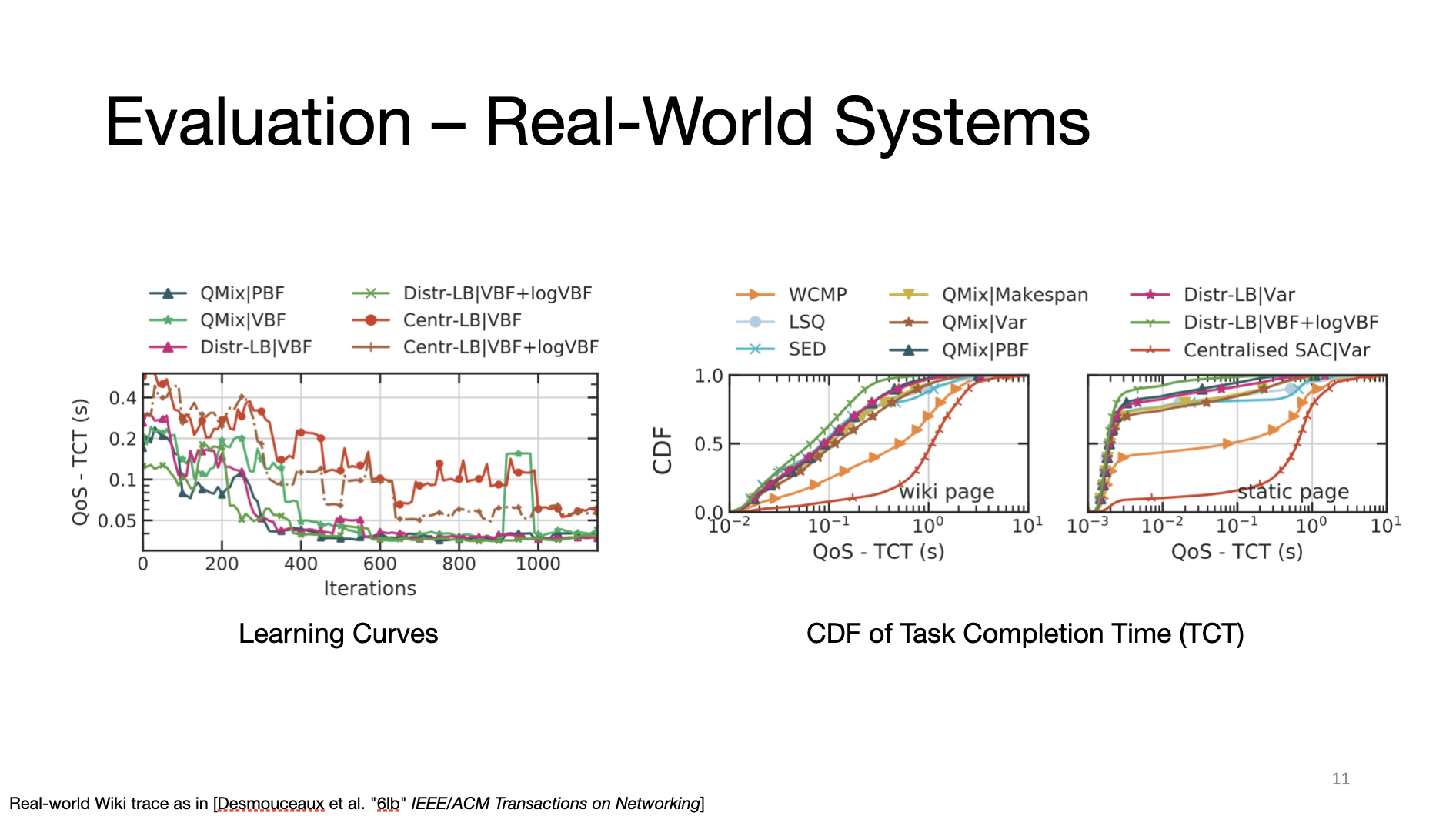
Experimental results show that our distributed Multi-Agent Reinforcement Learning framework using the variance-based fairness as rewards converges and effectively achieves better load balancing performance.
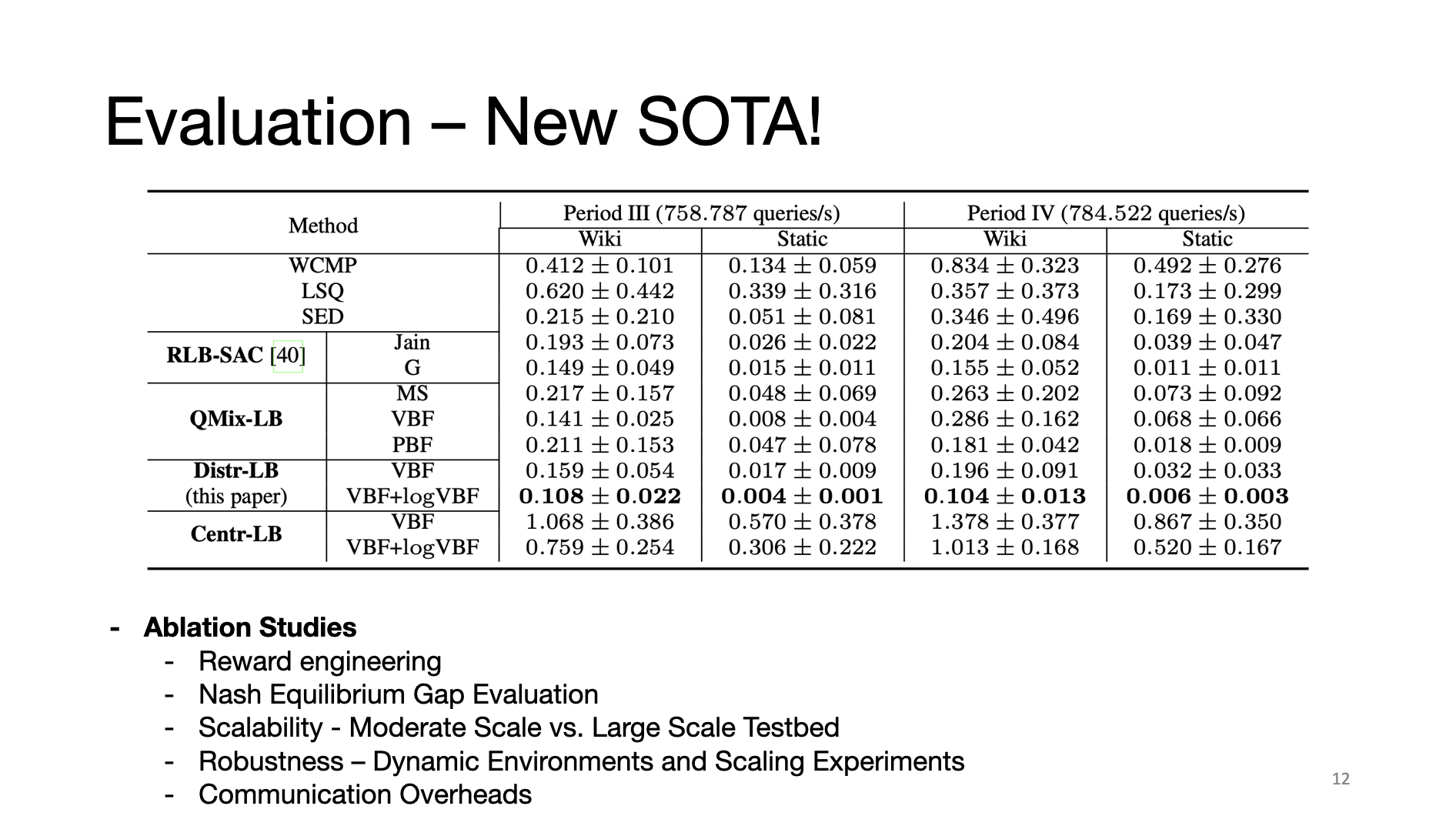
And we have shown that our method is the new state-of-the-art in terms of QoS than existing LB algorithms and CTDE RL algorithms.
In our paper, you will find more in-depth evaluations with respect to reward engineering, the evaluation of Nash equilibrium gap, scalability and robustness of the proposed load balancing algorithms and communication overheads.
Thanks

And this concludes my brief presentation of our paper. Thank you!
Discussion & Conclusion
I wrote this blog when I was attending the MASCOTS’22 in Nice France, which is the first and the last conference that I attended physically during my 3-year PhD study, because of Covid. I will write about my experience soon – which can not be better with the wonderful program committee, extraodinary attendees, outstanding papers and presentations, and the great weather and views in Nice. Stay tuned!
I wish I had the chance to attend NeurIPS in person. Well… maybe next time. I hope! ;)