FPGA 简介
我在P4 学习笔记(一)- 导论里面有提到过 FPGA,也就是 Field-programmable gate array(现场可编程逻辑门阵列)。FPGA 的主要特点就是介于 General Purpose Processor(GPP)和 Application-Specific Integrated Circuit (ASIC) 之间,同时结合了 GPP 的灵活性和 ASIC 的高性能的两大优点。 FPGA 的应用范围也很广泛,比如:科学计算、生物计算、人工智能、信号处理、信息安全等等。
FPGA 使得硬件变得越来越容易自定义(custom-designed),同时允许我们随时改变硬件的设计,兼具多样性(versatility)和可重复编程(reprogrammability)这两大特性。
说到可重复编程,我们通常会说 better to reconfigure than to configure,因为我们永远不能确定现在设计的程序永远、在任何地方都好用(如果真的可以的话就抬好了😭)。比如我们写的程序是用来给小朋友们画大饼,本来的程序是设计了最多可以给 65536 个小朋友画大饼,结果 2077 年,小朋友的数量猛增,我们不得不 reconfigure 我们的程序,让程序最多能支持 1048576 个小朋友。类似这样的因为甲方爸爸提出的不同需求改写并 reconfigure 的例子还很多,所以可重复编程是非常重要的一点。
我们平时常说的 reconfigure 通常指的是 compile time reconfigure (CTR),也就是平时写的比如 C 程序的 reconfigure。而 FPGA 还支持 runtime reconfigure (RTR)。因为 FPGA 上面有 virtual hardware,就像我们现在使用的计算机系统里的 virtual memory 一样,允许 partial reconfiguration。对于这个过程,我们之后会更详细的学习。
相较于传统的 System on a Chip (SoC) 的开发,FPGA 还适用于异构的分布式计算机架构,比如 Amazon 有 Elastic Compute Cloud 的 F1 instances,IBM 有 Power8 架构,微软有 Catapult,Ryft 有他们的 Ryft One Project 等等。
FPGA 的组成部分
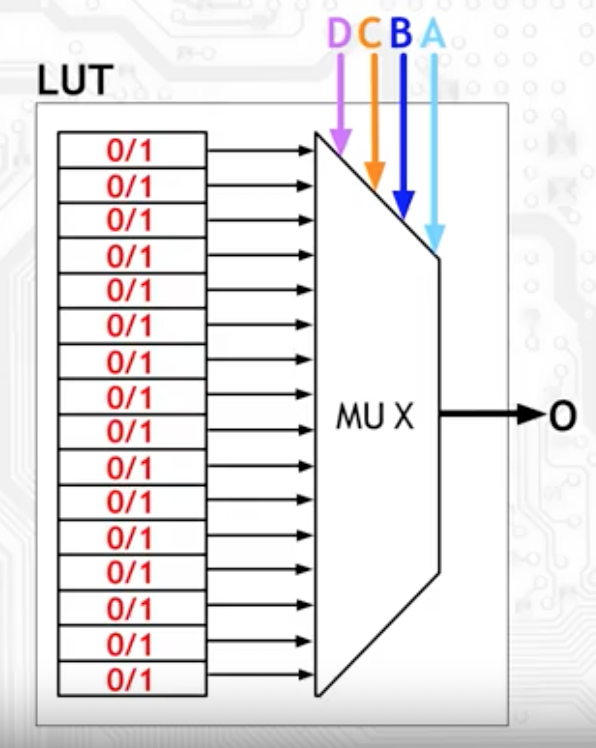
兼具 flexibility 和 accelerated 这两个特质的 FPGA 简单来说有三大组成部分:
- Configurable Logic Block (CLB): 这一部分是由 Look-Up Table (LUT) 组成的逻辑运算部分,又可以分为组合逻辑和时序逻辑和 sequential logic 两种;
- I/O Block (IOB): 这一部分用来传输和交换数据;
- Programmable Switch Boxes (Interconnections): 这一部分用来把上面两部分连接起来。

如上图所示,CLB 遍布 FPGA 的各个角落,IOB 就像是围在 CLB 四周的一圈端口,和外部环境交换数据,然后灰色的网格就代表了 Interconnections 的部分,把运算的 CLB 和输入输出的 IOB 编织在一起。
Workflow
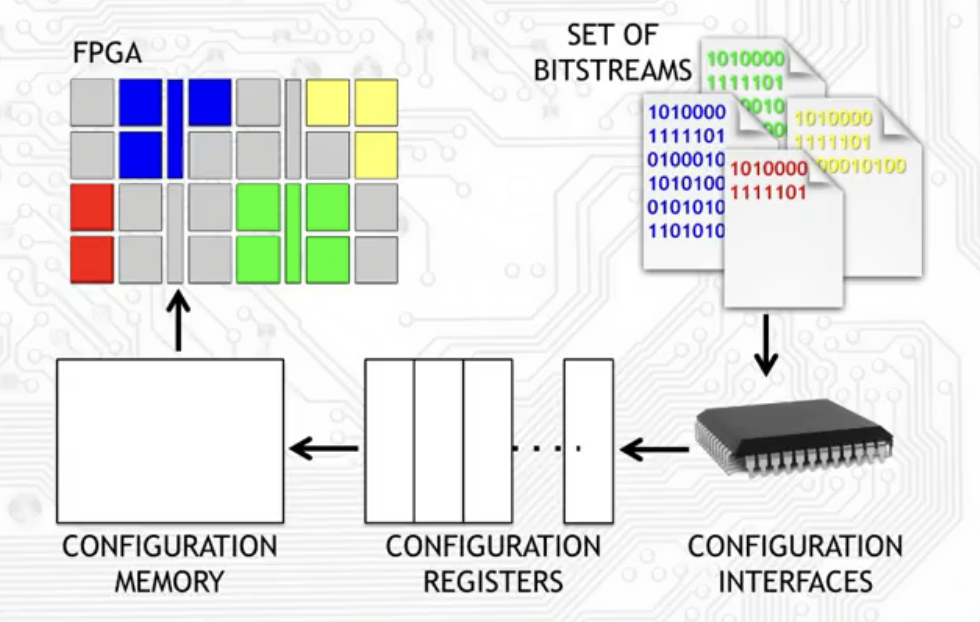
上面这个图就是 FPGA 整体 configure 的流程。从 bitstream,到 configuration interfaces,到 configuration registers,再到 configuration memory,所有的数据都是以 frame 为最小单位(smallest addressable segment)进行传递(on column-basis)。每一个 frame 的大小按照多少(n)个 32-bit word 来计算,不同的硬件有不同的 frame 大小。以 Xilinx 家的板子举例,Vertex 4/5 的 n=41,Vertex 6 的 n=81,Vertex 7 的 n=101。
下面我们一个一个步骤的简单过一遍 workflow。
首先,Bitstream 其实就是一系列 0/1 组成的字符串,它们可以是 full bitstream,也可以是 partial bitstream。Full bitstream 也就是把整个 FPGA 的板子的所有模块都 configure,而 partial bitstream 只 configure FPGA 板子的某一些部分。所以就像我们上面提到的,partial bitstream 允许 partial configuration,同时使 RTR 成为可能。
第二步里的 configuration interfaces,也就是把 bitstream 传到 FPGA 板子上的方式,一般会讨论不同的 mode 和 interface。比如有一种模式叫做 slave mode,在这种模式下,配置的 bitstream 文件存储在 master board 上,然后其他的 FPGA boards 可以从这个 master board 上拷贝同一份 bitstream 文件。至于 interface,bitstream 可以通过比如 JTAG 下载、或者 SelectMAP 来 daisy-chain 多个 FPGA 板子的配置过程,还有 compact flash card 上的 PROMs、或者基于 micro-controller、还有 Xilinx 的 internal configuration access point (ICAP),都可以作为 configuration interface。
第三步里的 configuration registers 定义了某一个时刻的 configuration logic 的状态。configuration registers 是一些可以被 bitstream 文件直接访问的内存。实际的 configuration data 会被先从 bitstream 文件里拷贝到这些 registers,然后再拷贝到 configuration memory (Configuration memory 是 Random Acess Memory (RAM),是 volatile 的)。Configuration memory 最终会决定 FPGA 每一个部分在我们设计的程序中扮演什么样的角色
FPGA 的研发过程
关于具体的 FPGA 研发,@老石已经发布过很多视频讲解过了,思路很清晰,推荐大家去围观!我在这里就简单记录一下,一共分为如下七个步骤。
第一步,就是写 hardware description languages (HDL)。有三种基本的语言可以用,VHDL、Verilog、和 SystemVerilog,每个大厂偏好的语言可能不太一样。在这三个语言的基础上,很多厂商也都支持软件语言的 API,让不太理解底层硬件结构的软件工程师也能做硬件编程。但就像我们平时可能会用到的语言一样,如果我们的老板突然让我半个小时之后帮他处理一波数据做个 ppt,那我可能会用 python 赶快写个脚本,quick but dirty。但如果我很在乎性能,那我还是会用 c 或者 c艹。HDL 也类似,如果只是想做一个 prototype 的话,可能用 C、Python、P4 之类的语言的 API 可以更快的实现一个设计,但真的要优化性能的话,还需要 HDL 的帮助。
用 HDL 写完程序之后,就可以开始 validation 了。在这一步,我们通常会跑一些 high-level simulations 来确认我们的程序设计的是否有问题。有没有超出我们预料的结果,比如 corner cases 有没有考虑到。同时,这一步可以帮我们确认 pin 脚的输出、和系统里别的部分的连接,还有性能如何。
再下面一步,就是 logic synthesis。这一步就是把 HDL 语言编译成逻辑门和 flip-flops。这个过程就像编译器一样,很复杂。这里就不展开了(俺也不太懂…)。
知道了我们需要什么样的逻辑门和多少个 flip-flops 之后,我们就要把他们映射到 FPGA 上实际存在的单元了,这一步叫做 technology mapping。以上一步的逻辑门和 flip-flops 作为输入,这一步的输出叫做 netlist,里面排列好了从库里面对应的 FPGA 上实际存在的单元,比如不同种类的 LUT。
有了 netlist,我们知道了设计好的程序需要多少个什么样的 LUT,但还不知道具体 FPGA 上的哪一个 LUT 会用来做什么,于是现在我们就需要两个紧密相关的步骤,placement & routing。这两步会决定 FPGA 上具体每一个 LUT 会用来实现我们程序中哪一步的运算,而这个 LUT 的输出又会被送到哪一个 LUT 作为输入。Placement 决定了 FPGA 上每个单元模块应该对应哪一个运算过程、放在什么位置,routing 决定了运算过程之间如何连接起来最节约传输时间,这两步互相影响,这也是为什么我们说他们是紧密相关的两个步骤。
完成了上一步之后,我们要做 time analysis,也就是分析一下比较重要的运算过程,或者说是 critical region,在 FPGA 板子上实现之后会不会有很高的延迟,如果有延迟的话,我们就应该回过头去优化这个 critical region 来获得更高的性能。
等到上面所有的步骤都完成之后,经过上面无数次的调试、优化的流程… 我们就终于可以 generate bitstream,然后真正的 configure FPGA 的板子(真的太难了…)。
FPGA 开发工具
看到了上面这么多复杂的开发流程,我们很容易心生畏惧,但 Xilinx 告诉我们不用害怕(希望 Xilinx 有朝一日能给我点广告费)。他们每年都会投入很多的 $$$ 来研发 user-friendly 的开发工具,比如 HLS、SDx 这两个系列的工具。
很久很久以前,硬件开发人员需要盯着波形图和时钟看,分析硬件实现有没有问题。这样的方式对于相对简单的应用来说也许可以接受,但是随着设计和应用场景变得越来越复杂,这样的方法不够高效,而且很难让我们得到最优解(比如 placement & routing 的优化)。除此之外,有的应用可能会要求我们使用多核心多线程甚至异构计算结构,这个时候开发工具就更加不可或缺了。借助着这些工具,我们的研发过程就好像站在巨人的肩膀上,助益颇丰。
就像我们开发 C 语言的程序,使用 GDB (GDB thread facilities) 能极大的帮助我们检查(多线程)有没有内存泄漏的问题,Xilinx 的工具也可以高效的帮我们优化我们的硬件设计。比如 SDNet 是高性能网络硬件设备开发工具,SDSoC 可以帮助开发新的 SoC 或者 Multiprocessor SoC (MPSoC) 应用,SDAccel 用来加速数据中心网络中的应用程序。至于如何获取这些工具,之后有时间会记录一下我自己申请 license 的过程。
小结
这篇文章里,我们简单介绍了一下 FPGA 的特点、组成、工作流、研发周期、和开发工具。最后再总结几个重点:
- Reconfigurable computing 可以帮助我们权衡更短的设计周期和更高的性能;
- FPGA 可以针对不同的目标系统给出 reconfigurable logic 来实现系统适配;
- FPGA 能够实现 RTR 是因为我们可以选择只 reconfigure 板子上的一部分逻辑门;
- 一个有多个 FPGA 设备的系统可以在每个 FPGA 上实现独立的程序,也可以用几个 FPGA 板子协同实现同一个应用程序;
- FPGA 上面有三大组成部分:CLB、IOB、和 Programmable Switch Boxes,各自负责逻辑运算、输入输出、和 interconnection;
- Configuration frames 是 FPGA 上 configuration memory 的最小数据单位;
- 数据在 FPGA 上是按照 column-basis 来加载的;
- 我们可以在分布式系统里通过 slave configuraiton mode 远程配置 FPGA;
- 除了 HDL 语言,类似 C、Python 这样的软件语言可以协助我们定义 high-level functionality;
- Technology mapping 只会告诉我们设计的 functionality 需要什么样的技术元件(比如 LUT),但不会告诉我们具体用 FPGA 上的哪一个元件;
- Placement & routing 的过程会确定具体哪个板上元件会被应用于哪个 functionality,并且这一步骤的结果会直接影响 time analysis 的分析结果(比如 processing latency);
- Xilinx SDx 工具让我们能够引导硬件 kernel 进行编译和 synthesis 来得到更高的性能;
参考
Developing FPGA-accelerated cloud applications with SDAccel: Theory