
- Link2Paper
- [Author: LiChen et al.]
- [Keywords: Datacenter Networks, Reinforcement Learning, Traffic Optimization]
Motivation
Traffic optimizations (TO) are very difficult online decision-making prolems. Previsously, They are done with heuristics relying on operators’ understanding of the workload and environment. Encouraged by recent success in applying Deep Reinforcement Learning (DRL) techniques to solve complex online control problems. Li wants to use DRL to automatic TO without human-intervention.
Related Work
PIAS [1]
Under mismatch scenarios, performance degradation can be as much as 38.46%.
pFabric [2]
pFabric shares the same problem when implemented with limited switch queues: for certain cases the average flow completion time (FCT) can be reduced by over 30% even if the thresholds are carefully optimized.
[3]
Routing and load balancing on the Internet have employed RL-based techniques since 1990s. However they are switch-based mechanisms, which are difficult to implement at line rate in modern datacenters w/ > 10GbE links
[4]
RL techniques are used for adaptive video streaming in Pensieve, which is a system that generates bitrate adaptation (ABR) algorithms using RL.
[5]
Machine learning (ML) techniques are used to optimize parameter setting for congestion control. But parameters are fixed with a set of traffic distribution and no runtime adaptation is allowed.
CODA [6]
CODA uses unsupervised clustering algorithm to identify flow information without application modification. But the flow scheduling decisions are made by heuristics with fixed params.
Contribution
Problem
Current DRL systems’ performance is not enough to make online decisions for datacenter-scale traffic. They suffer from long processing delays even for simple algorithms and low traffic load.
Solution
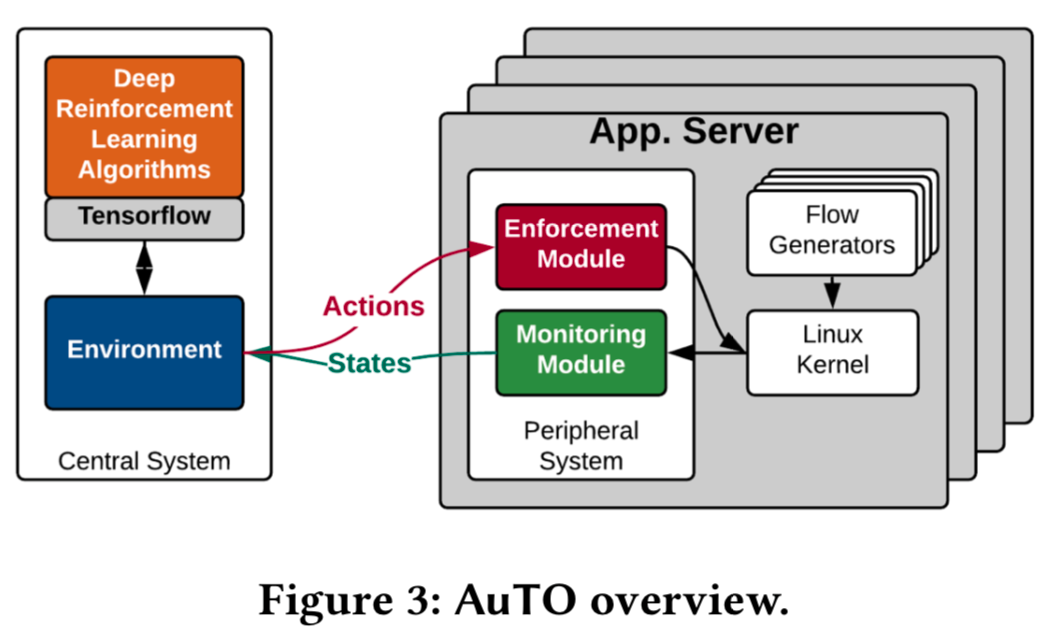
In order to leverage the long-tail distriubtion of datacenter traffic (most of the flows are short flows while most of the bytes are from long flows, meanwhile long flows TO decisions consumes more time), the authors develop a two-level DRL system, namely Peripehral System (PS) and Central System (CS).
- [PS] PS resides on end-hosts, collects flow information, and make TO decisions locally, with minimal delay for short flows.
- [CS] CS makes TO decisions for long flows, and PS’s decisions are informed by CS where global traffic information are aggregated and processed.
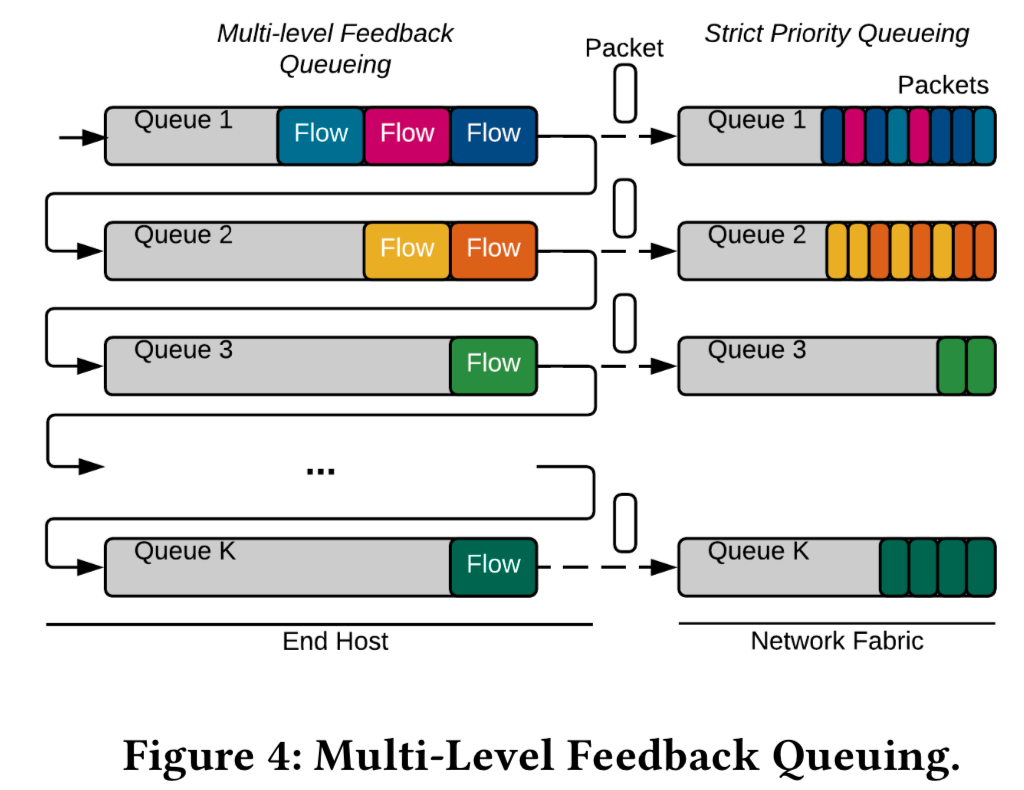
Multi-Level Feedback Queueing (MLFQ) is adopted for PS to schedule flows guided by a set of thresholds.
Two different RL algorithms are used for short flows (choosing MLFQ thresholds) and long flows (threshold that separates long flows from short flows).
Evaluation
They mainly evaluated average and p99 FCT in different scenarios for performance. System overhead is evaluated by response latency for CS and by CPU utilization for PS.
Limitation
- Throughput oriented optimization
- Limited proof on scalability
Ref
- [1] Information-Agnostic Flow Scheduling for Data Center Networks
- [2] pFabric: Minimal Near-Optimal Datacenter Transport
- [3] Packet routing in dynamically changing networks: A reinforcement learning approach
- [4] Neural Adaptive Video Streaming with Pensieve
- [5] Tcp ex machina: Computer-generated congestion control
- [6] CODA: Toward automatically identifying and scheduling coflows in the dark